| 2017-11-11
2017年11月06日-08日,第16届OpenStack峰会在悉尼成功举行。UnitedStack同方有云,中国最早的 OpenStack 开源云计算公司之一,作为黄金会员赞助并出席了本次峰会。同方有云的工程师团队为峰会带来了来自中国公司的主题分享,其中高级工程师姚宁的分享主题为《大规模生产环境下Telemetry的使用》。

Telemetry 是 OpenStack 的监控计量项目,原项目称为 ceilometer,它需要完成数据采集、数据存储、数据查询、监控告警策略等一系列的逻辑,因此该项目也越来越庞大,导致其越来越难维护,故从 Liberty 版开始,社区将其逻辑进行拆分,并衍生出了 4个项目, 分别为 ceilometer,gnocchi,panko,aodh,而这4个项目统称为 Telemetry。
由于 Telemetry 在 OpenStack 生态圈中,使用的人较少,而本次的重构拆分和迭代的版本

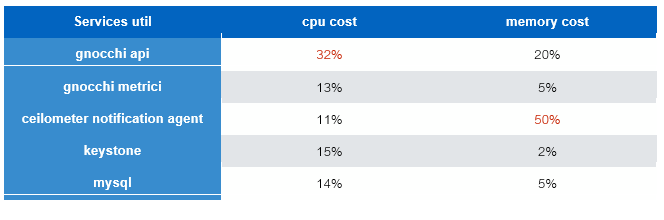

首先,我们来看一张图显示的测试结果:
从上图可知,我们在 3控制节点,6计算节点的环境下,创建出了 2000 台虚拟机。然而控制节点上面 cpu 的利用率达到了 70% 以上(gnocchi-api 使用率最高),内存的利用率达到了 80% 以上 (ceilometer 使用率最高),且计算节点上,Ceph 后端磁盘上的压力达到了 SSD 磁盘带宽的 90% 以上。那么到底是什么造成了这样的结果,分析如下:
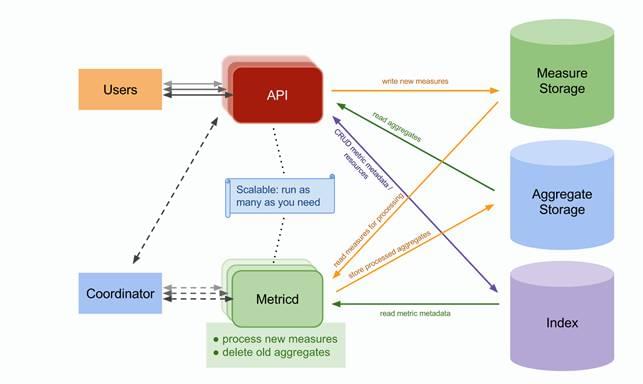
首先,针对Ceph 存储带宽被耗尽的问题,Gnocchi 后端存储 3种类型的数据,Measure Storage 存储从 API 发来的临时的 Measure 数据;Metricd 通过对 Measure Storage 中数据进行聚合,形成可查询的时序数据,存储入 Aggregate Storage;Index Storage 用于存储元数据,从而组织起有哪些 metrics 监控项,这些 metrics 属于那个 resource 等等。
但是,在 P版本之前,Measure Storage 和 Aggregate Storage 只能使用同一种后端,如果配置了 Ceph 那么就必须使用 Ceph,可是 Ceph 在 Measure Storage 存储数据的时候,有一个很严重的问题是 Ceph 将 Key-Value 的数据都存储在了 Rocksdb/LevelDB 中,而 Rocksdb 和 Leveldb 具有极大的读写放大,根据测试结果,Rocksdb 中写入 45G 用户数据,可能被放大成 1868GB,放大系数高达 42倍,如下图:
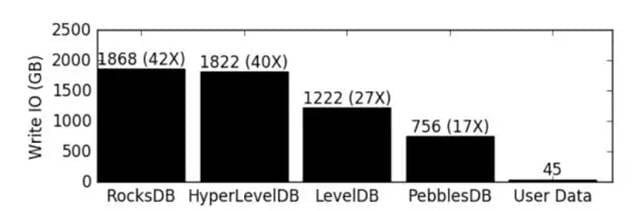
而对于高频率,高读写的临时 Measure 数据,是非常不适合存储在 Rocksdb 中,这是导致底层磁盘带宽过度消耗的主要原因。所以我们能做的就是将 Measure Storage 和 Aggregate Storage 的后端分离,Measure Storage 后端使用 redis,而 Aggregate Storage 的后端使用 Ceph,在 P版中配置如下:
[incoming]
redis_url = ${storage.redis_url}
[storage]
driver = ceph
ceph_pool = gnocchi
ceph_username = None
ceph_secret = None
ceph_keyring = None
ceph_conffile = /etc/ceph/ceph.conf
其次,如果我们使用 Ceilometer 进行数据收集,假设我们有 3 个 ceilometer notification agent,那么,如下图所示
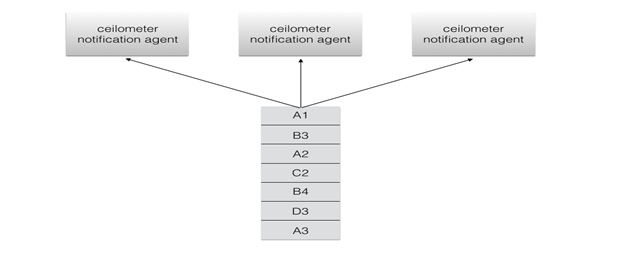
其中,A,B,C,D 代表每个 metric 监控项,A1 代表第一次监控数据,A2 代表第二次监控数据。然而,可能出现的情况如下:
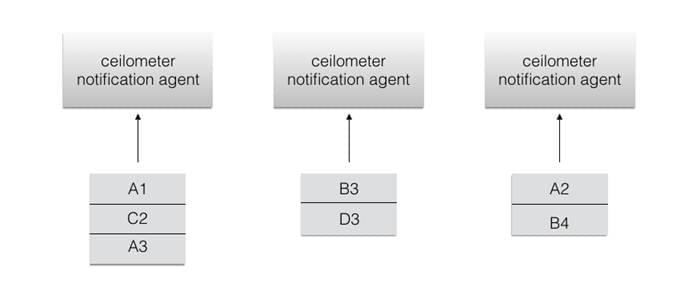
A 监控项的数据分布到了两个不同的 ceilometer agent 上面,那么如果我们需要计算磁盘 IO 速率这种指标,disk read per second: ∆𝒙 / period,这里 ∆𝒙=A3 - A1。∆𝒙 与我们原先希望的 A2 - A1 不同,而且由于我们需要计算差值,就必须存储所有监控项的上一次差值,那么在这种情况下,第一个 ceilometer agent 会存储 A 监控项上一次的值 A1,而第三个 ceilometer agent 上面也会存储 A 监控项上一次的值 A2,这就导致了到虚拟机和监控项数据增加的时候,ceilometer notification agent 的内存使用率将直线增加,从而严重影响水平可扩展性和资源效率。
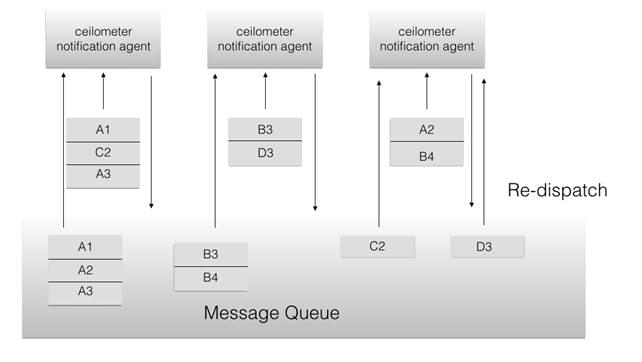
所以我们需要正确配置 workload_partitioning,使得不同监控项到达 ceilometer notification agent 以后能够被重新分发进以监控资源为关键字索引的队列,然后让特定的 ceilometer notification agent 去处理,这样就保证了一个监控项中的值最后只会被特定的 ceilometer notification agent 处理,如下图所示:
最后,就是 ceilometer 向 gnocchi 传输数据的时候,使用 http 协议的问题,这导致了平凡更新的监控数据高频率的调用 API,而 API 调用操作是一次非常重量级的操作,需要和 keystone,数据库等多个后端组件交互,严重影响的单控制节点对请求的处理效率,消耗大量的 cpu 计算时间。我们在这里提出,监控数据应该使用 UDP 协议来进行传输上报,如何调优及使用,我们将在下次继续介绍,有兴趣的小伙伴们请持续关注我们。
在优化后,我们平台能够承载的虚拟机数量和监控项数量大幅度增加,如下图所示:
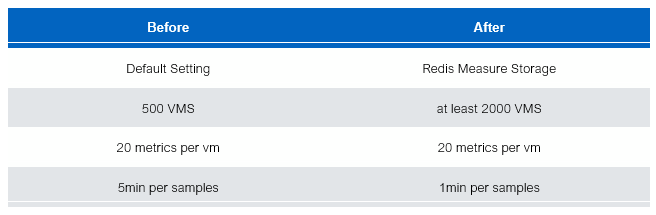
原先平台只能支撑 500 台虚拟机(每台虚机 20个监控项),以每 5分钟一个采样点进行采样监控。经过优化,在同样的情况下,我们可以轻松的支撑 2000 台虚拟机 1分钟一个采样点进行采样。
总结,目前 Telemetry 项目在真正的使用中,成熟度仍然欠佳,但是我们也看到了 Telemetry 项目的持续发展 和 走出困境的决心,并且在你能够深入的掌控和很好的配置且使用 Telemetry 的情况下,它已经能够承载小规模或一定规模集群的监控告警和计量任务,有兴趣的小伙伴们快来试一试吧。


